As we welcome the year 2024, we wanted to update you on what we have been
working on in the second half of 2023 and announce the new features that are
launching today. These changes will have a profound impact for our customer
workflows and our own detection and classification abilities.
Saved Searches — A success story
When we launched Saved Searches in 2022 for our scans and hostnames
feeds, we did not envision how popular this feature would turn out to be.
Initially, Saved Searches were meant as a convenient way to bookmark a search
term within the urlscan Pro platform. The Subscriptions feature allowed
customers to receive notifications for any new items that matched their Saved
Searches.
Over the past year, the value of Saved Searches to customers has become
abundantly clear. Right now we manage more than 3000 Saved Searches and almost
1000 Subscriptions that have been created by our customers. Our subscription
notification system sends out over 5000 emails a day.
Saved Searches and Subscriptions became even more important when we launched
our Newly Observed Domains & Hostnames
Feed in late 2022 and
urlscan Observe earlier this
year. Since then, many of our customers have set up Saved Searches to look for
domains impersonating their brand or targeting their workforce. Our feed
captures 2.5 million new domains and hostnames every day, so having an
expressive search ability to find and alert on interesting hits is crucial.
Today we are launching major improvements for Saved Searches, Subscriptions and
collaboration within the urlscan Pro platform.
Saved Searches Before
Until now, Saved Searches and Subscriptions were basically just stored entries
in a database. In order to alert on a Saved Search, we would run its full query
term against the Search API every time we wanted to compile a list of hits.
While this approach would yield the correct results, it was not great for
multiple reasons:
- As the number of Saved Searches grew, we had to run thousands of queries,
sometimes as often as every few minutes.
- Our own Visual Detects and Deletion rules used the same timed method for
querying, resulting in a delay of 1-2 minutes before a Visual Detect was
applied or a scan was deleted.
- Customers could not easily determine if a specific result returned by Search
API did match any of their Saved Searches.
We knew that we had to improve the implementation of Saved Searches
and Subscriptions if we wanted to continue scaling our platform and user base
and offer more advanced features.
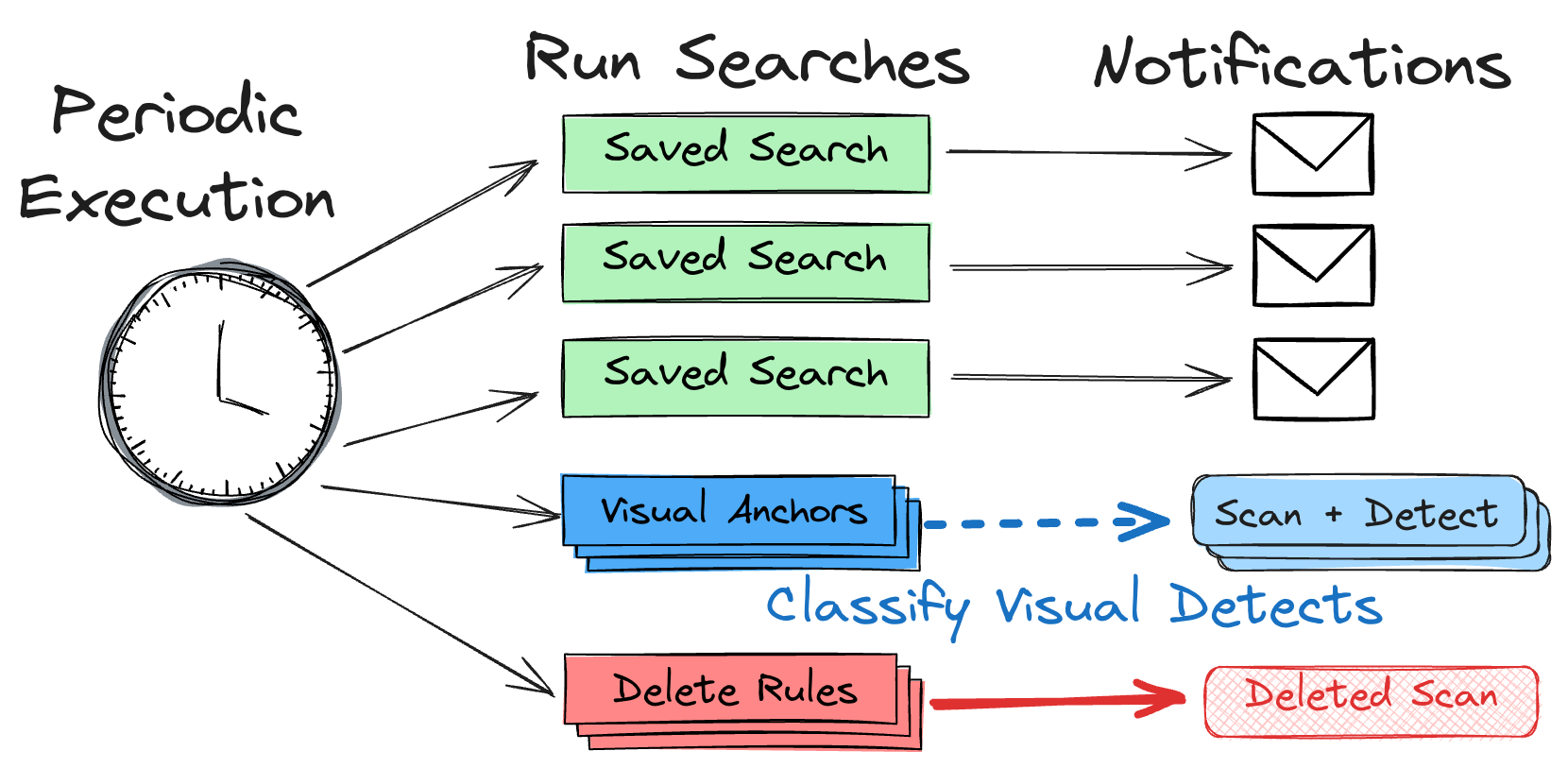 Our old saved search workflow
Our old saved search workflow
Saved Searches Now — Inline matching
As part of this release, we have changed Saved Searches so that they are now
executed inline against new scans, hostnames and domains entering our
feeds. Elasticsearch calls this process “percolation”. Whenever urlscan
performs a new scan or finds a new domain, it is executed against
various types of stored rules in two passes:
- During the first pass, urlscan applies its
own block-and-delete rules, its brand-and-phishing detections, and its new
System Labels (see next paragraph).
- During the second pass, we
execute the thousands of Saved Searches by our customers. Matching searches are
recorded in a special
meta field in our Elasticsearch index. Customers can
then query this meta field with the ID of the search (or subscription) they
want to retrieve new results for.
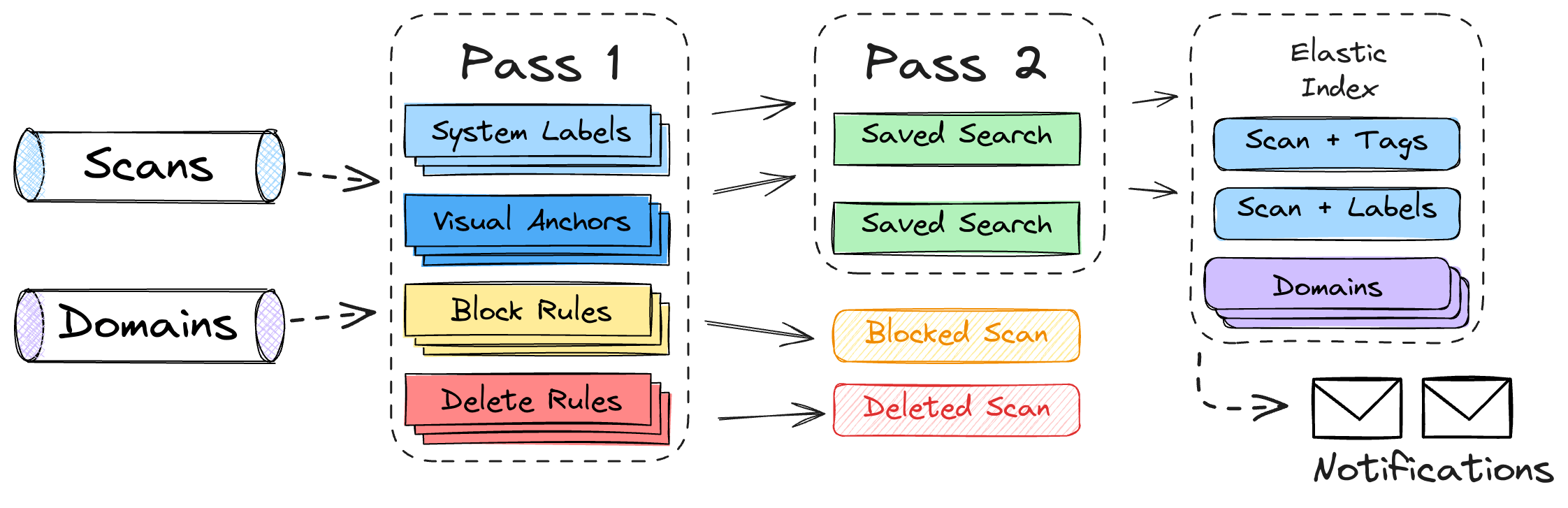 New inline matching pipeline
New inline matching pipeline
As part of a Saved Search, customers can also apply their own custom tags to
matching items. These can be arbitrary tags, and customers can control the
visibility of these tags within the urlscan Pro platform. User-supplied tags
will appear in the usertags fields in the Search API and Result API.
New customer capabilities
Executing and matching rules inline has a couple of interesting implications:
- Customers can query for all items that match multiple specific searches,
or that match one search but don’t match another one.
- Customers can query for all items that match any search within a specific
subscription with a single query term, or any of their searches period.
- When looking at search results, customers can determine whether any
particular result matched any of their Saved Searches.
- Customers can use labels from the first matching pass in their
Saved Searches, e.g. to filter by system labels or brand detections.
- Customers can share results of their Saved Searches with other users on the
urlscan Pro platform without exposing their actual search terms.
- Complex queries could easily take multiple seconds to execute. With inline
matching, the expensive matching step is done during ingestion and the
customer can run a very efficient keyword query to retrieve all results.
- Visual Searches can also be run inline, making them much more efficient and
instant. Inline Visual Searches will be more accurate than using the Visual
Search API which relies on approximate nearest-neighbour searches.
System Labels
System Labels are classifications applied to scans and hostnames by dynamic
rules managed by urlscan. Labels will be returned in the labels field which
is a different namespace than user-defined tags. The idea for labels is that
these are stable and exhaustively documented, whereas user tags can be
arbitrary, short-lived and in some cases imprecise.
Going forward, we will curate labels covering common classification objectives that
our customers can use to include or exclude from their search results. Here
are some examples of labels for scans we plan on introducing:
content.mature - Page likely contains mature content.content.opendir - Page is showing an open directory.site.parkeddomain - Domain is currently parked / for sale.site.takedown - Site is showing a takedown / disabled-account notice.tech.captcha - Site employed a captcha prompt.tech.captcha.waiting - Site is showing an unsolved Captcha prompt.
These are just some initial ideas and we know our customers will come up with
all kinds of creative ways they want to consume our data.
Additional Benefits
With Inline Matching in place, we were able to improve various aspects of our
platform. For customers, the most visible changes include:
- Saved Searches are sanity-checked before we allow them to be saved. Trying
to search fields which don’t exist will now throw an error.
- Account-protection for scans — Upon request, we can restrict access
to scan results to the owner of that account. (Feature available in
Enterprise and Ultimate).
- Improved Brand Detection — We will use the expressiveness of our
inline matching to craft more encompassing detection rules for our brand- and
phishing-feed.
- Instant Visual Detections — Visual Detects for phishing pages are now
performed instantly. Previously these would have a small 1-2 minute delay.
- Instant Deletion — Once we add a block-and-delete rule, it is
effective immediately for scan results.
- Unified Blocking Logic — URLs that are blocked from scanning are
maintained by us in a unified way along with delete rules. These blocking
rules also contain more context about why a certain URL or hostname might be
blocked.
Next steps
We are launching inline matching today, but for us this is just the first step
of many. Over the coming weeks and months we will examine how our customers are
adopting the new features and what they might be missing. We will also expose
these new capabilities gradually via our urlscan Pro UI. Make sure to keep an
eye on our changelog!
API Changes
On top of the new features launching with this release, we also made small
improvements to the platform in various places. This is a summary of changes
to API behaviour within this release:
- Result API: If a scan has finished but has since been deleted it will now
return a HTTP/410 error code. If you receive this code from the Result
API, you can stop trying to retrieve the result.
- Result API: Introduction of the following new fields to achieve more uniformity with the Search API:
labels: System Labels (see above) - Only in urlscan Prousertags: User Tags (see above) - Only in urlscan Prometatags: Meta hits for this item - Only in urlscan Pro (Attention: This field is called meta in the Search API)page.apexDomain: The registered second-level domain of the page hostnamepage.mimeType: Page MIME typepage.redirected: Whether the page was redirectedpage.status: HTTP response code for primary pagepage.title: Title of the websitepage.tlsAgeDays: Age of the TLS certificate at the time of scanningpage.tlsIssuer: TLS issuer name for the TLS cert of the pagepage.tlsValidDays: Validity period of the TLS certificate in dayspage.tlsValidFrom: ISO 8601 timestamp of valid-from date for page TLS certificatepage.umbrellaRank: Cisco Umbrella rank of the page hostnametask.apexDomain: The registered second-level domain of the task hostname
- Search API: Introduction of the following new fields:
labels: System Labels (see above) - Only in urlscan Prousertags: User Tags (see above) - Only in urlscan Prometa: Meta hits for this item - Only in urlscan Pro (Attention: This field is called metatags in the Result API)
- Search API: It will now respond with HTTP/503 instead of HTTP/400
if our search cluster is over capacity. You should wait a few seconds before
attempting to run your search again.
Availability
Inline Matching, User-Defined Tagging and System Labels are available starting
today and is included for all customers on our Professional, Enterprise and
Ultimate plans.
If you want to learn about urlscan Pro platform and how it might be valuable
for your organisation feel free to reach out to us! We offer free trials with
no strings attached. We would be happy to give you a passionate demo of what
our platform can do for you. Reach out to us at
sales@urlscan.io.
]]>







